Side-by-side · one page · cited cells
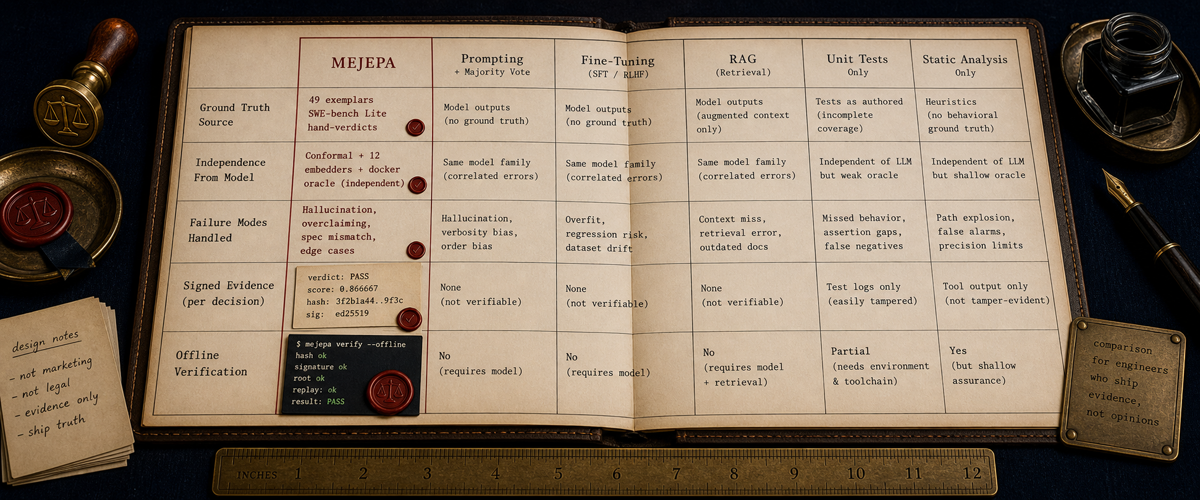
How Mejepa is different.
Eight dimensions. Five alternatives. Mejepa cells cite the FSV plan; competitor cells cite public documentation. Cells without a defensible public source are marked "not publicly disclosed." Refresh date: 2026-05-20.
| Dimension | MEJEPA | CodeRabbit | Greptile | SonarQube | AI self-grading | Senior reviewer |
|---|---|---|---|---|---|---|
| Ground truth source | Docker oracle on SWE-bench Lite, per-instance report.json SHA-256 in the signed packet |
LLM-generated review comments | LLM agent reads codebase, summarizes PR changes | Rule-based static analysis (security CWEs, code smells, complexity) | The same model that wrote the code grades the code | Human judgment, ~50 lines per minute |
| Verdict shape | Pass / Fail / Abstain + named failure mode + closest exemplar | Natural-language review comments + suggestions | Natural-language PR summary + comments | Rule violations + severity (Blocker/Critical/Major/Minor) | "Looks good to me" + optional comments | Approve / Request Changes / Comment |
| Falsifiable? | Yes — predicts oracle outcome before merge; correlation measured weekly on 8/30 holdout | No — natural-language opinion | No — natural-language opinion | Partial — rules are deterministic, but rule coverage is not the same as patch correctness | No — same model produces assertion and grade | Partial — reviewer can be checked against post-merge outcome, but not at scale |
| Independent verifiability | ed25519 + SHAKE-256 witness chain; replay offline in ~30s with the published public key | Not publicly disclosed | Not publicly disclosed | Audit-quality reports exist; signed witness chain: not publicly disclosed | None — no audit artifact | Reviewer's name on the PR; auditable at sample, not at scale |
| Languages (at ship-gate) | Python only at ship-gate; capture infrastructure multi-language | Multi-language (Python, JS, TS, Go, Java, …) | Multi-language | ~30 languages | All languages the underlying model supports | Limited by reviewer fluency |
| Agent integration | 57 mejepa_* MCP tools; integrates with Claude Code, Cursor, Windsurf, Cline, Continue, Replit |
GitHub PR comments, webhook integrations | GitHub / GitLab / Bitbucket integrations | CI plugins for major build tools | N/A — runs inside the agent | Out-of-band human workflow |
| Pricing posture today | Founder-fielded pilots only; per-engagement; hosted offering fenced until ship-gate green | Per-developer SaaS subscription | Per-developer SaaS subscription | Community / Developer / Enterprise tiers | Included with agent | Engineering-org cost; not unit-priced |
| Pick this when… | An auditor, insurer, customer, or counsel asks "how do you know the AI got this Python code right?" | You want inline LLM commentary on PRs | You want a codebase-aware LLM that reads the whole repo before commenting | You want long-established static analysis and quality-gate enforcement | Speed over independent assurance | High-stakes patch where a human in the loop is non-negotiable |
Mejepa is complementary, not replacement
Use Mejepa when an external party needs to replay the patch's verdict offline and confirm it themselves. Keep CodeRabbit or Greptile for natural-language critique inside the PR. Keep SonarQube for static-rule gating. Keep human reviewers for high-stakes judgments. Mejepa's job is the signed receipt — the one a stranger can verify without trusting Mejepa.